
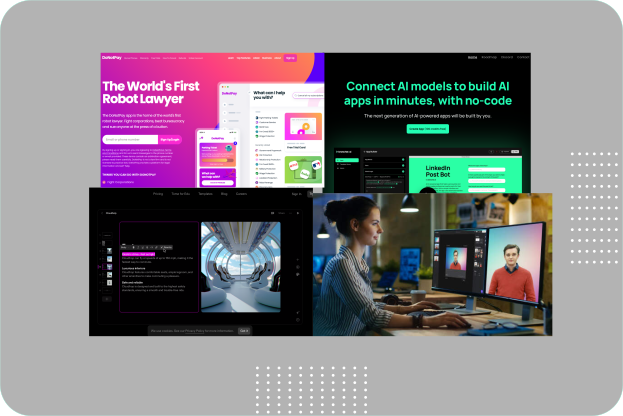
Beyond ChatGPT: Here are 6 AI-powered apps to try right now to make your life easier.
Introduction
As technology continues to advance, artificial intelligence (AI) is becoming increasingly prevalent in our daily lives. The way we engage with technology is changing thanks to AI-powered apps, which such as chatbots and personal assistants. In this article, we’ll explore the best 6 AI-powered apps to try in 2023.
Deepbrain.io
Create AI-generated videos using basic text instantly
Generate realistic AI videos quickly and easily. Simply prepare your script and use deepbrain Text-to-Speech feature to receive AI video in less than 5 minutes.

With deepbrain you can:
- Use custom-made AI avatar that best fits your brand
- Use Intuitive tool that’s super easy for beginners
- Save time in video preparation, filming, and editing
- Reduce cost in the entire video production process
AI Avatars
The AI Studios has AI avatars collection contain more than 100 native AI avatars from different professions. All avatars are available in 80+ languages. You can use these avatars to create your videos.
Try deepbrain
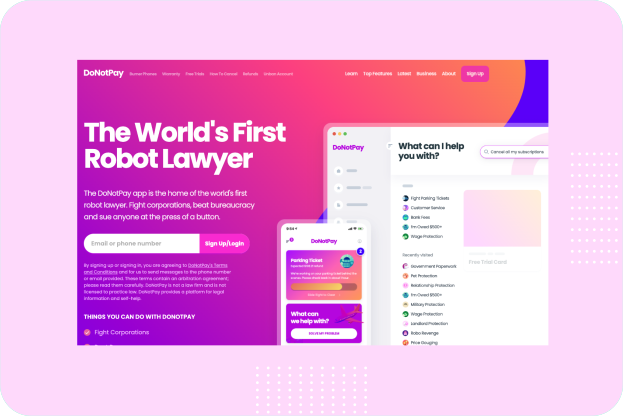
Donotpay
DoNotPay utilizes artificial intelligence to help consumers fight against large corporations and solve their problems like beating parking tickets, appealing bank fees, and suing robocallers.
DoNotPay could be your first choice of solving problems it has useful features including:
- Finding unclaimed money under your name
- Putting an end to spam emails
- Handling unpaid bills
- Jumping the phone queue when contacting customer service reps
- Fighting your parking tickets
- Getting a refund from any company
- Blocking spam text messages
- Dealing with your credit card issues and more.
Try donotpay
Canva
If you are you looking for ways to enhance your business marketing strategy then Canva is an excellent tool. Canva is a powerful graphic design tool that can be used to create stunning visuals for marketing and advertising purposes. Use high-quality images, colors, and typography to make your designs stand out. With Canva online tool you can create:
- Social media graphics
- Infographics
- Emails for Marketing
- Posters and Flyers
- Business Cards
- Presentations
- E-Books and Guides
- Logo and Branding
- Website Templates and Graphics
- Videos
Try Canva
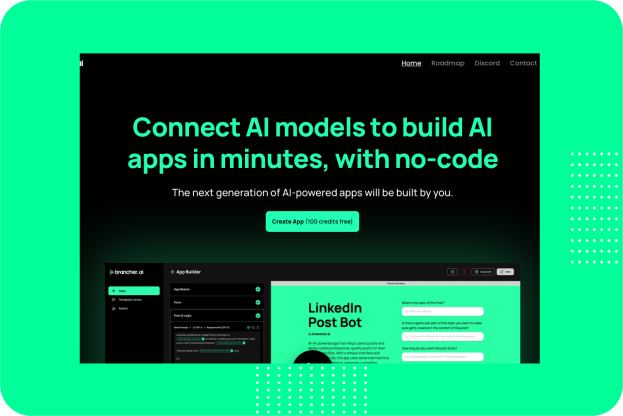
Brancher ai
Brancher.ai is a platform that enables users to connect and use AI models to create powerful apps without the need for coding knowledge. With this app you can create AI-powered apps quickly and easily. Brancher.ai comes with wide range of tools and features make it easy to create powerful apps without the need for coding expertise.
Try brancher.ai
Notion
Notion is a powerful all-in-one productivity tool that allows users to create, manage and organize notes, tasks, databases, wikis, and more, all within a single interface. It offers a wide range of features including text editing, tables, calendars, and integrations with other apps.
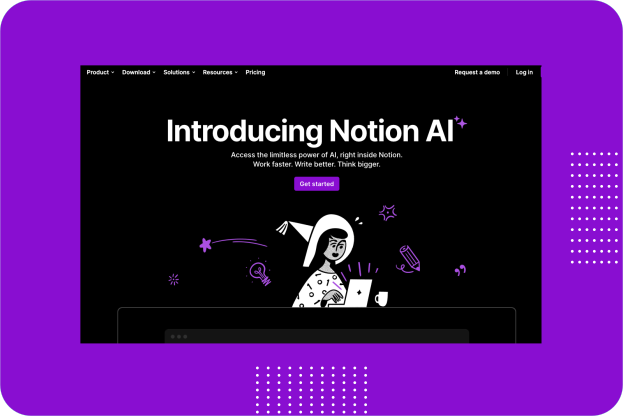
Notion is popular among individuals and teams who need a centralized platform for their workflows, project management, documentation, and collaboration.
Notion AI is completely redesigned so you can access the limitless power of AI, right inside it. With this feature you can work faster and write better articles for your blog.
Try Notion
tldv.io
This app is powered by GPT which can be used as meeting recorder that transcribes & summarizes your calls with customers, prospects, and your team. This tool will instantly summarizes your meeting topics, so you can stay focused on your conversation.
You can use this tool to:
- 🎥 Record Google Meet presentations and meetings automatically in top quality
- 💬 Receive highly accurate Google Meet transcription with Speaker Tags
- 🌎 Transcribe Google Meet transcriptions into 20+ languages
- 📌 Timestamp and highlight important call moments
- 🔗 Share links to recordings automatically to Slack and E-Mail
- 🔍 Search your call library for any word spoken in meetings and more…
Try tldv.io
Wrap up
Today, our lives are entirely dependent with these AI-powered apps, which provide a variety of features and advantages that improve our productivity. With the tools listed in this article, you can gain the power of AI for yourself and discover how it can enhance your productivity, creativity, and overall user experience.
Disclosure: Some of the links in this story are affiliate links, which means that I may earn a commission if you click on the link or make a purchase using the link. I only recommend products or services that I have personally used or that I believe will add value to the readers.
