
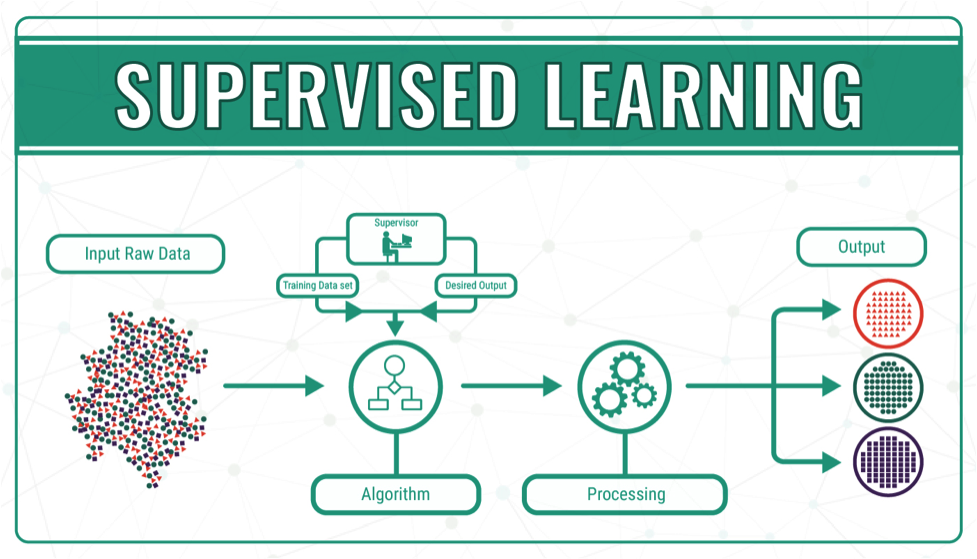
What is Supervised Learning?
Supervised learning is one of the most common paradigm for machine learning problems. The algorithms used in supervised learning are easily understandable, so it is more common.
When we teach kids, often we show flash cards, objects and several examples. They try to learn new things during that process. We then show similar things to kids and ask different kind of questions in order to understand the learning progress.
The same procedure will be applied during supervised learning. We train algorithms using large data sets. Some data are labeled with the correct answers. These labels or targets are known as features. Therefore we know the right answer before we train any model.
Supervised learning mostly consists of classification and regression. However there are other variant as well.
Let’s understand more…

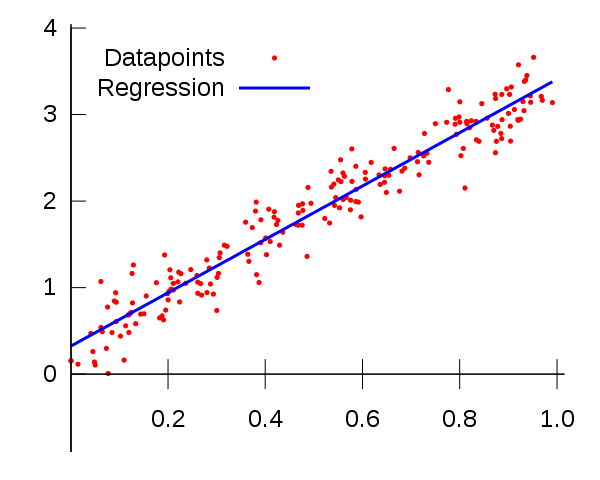
Regression
Predicting the price of a car for a given feature set (milage, color, brand etc). Some regression algorithms can be used for classification as well and vice versa. For example, Logistic Regression can be used for classification. It can output a value that corresponds to the probability of belonging to a given class (eg., 20% chance of being spam).
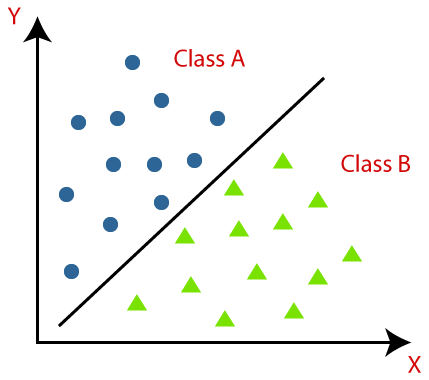
Classification
Classification is the process of predicting the class of given data points. Some examples of classification include spam detection, churn prediction, sentiment analysis, classifying hand written characters and so on.
Sequence Generation
Given a picture, predict a caption describing it. Sequence generation can sometimes be reformulated as a series of classification problems (such as repeatedly predicting a word or token in a sequence).
Object Detection
Given a picture, draw a bounding box around certain objects. This can also be expressed as a classification problem (given many candidate bounding boxes, classify the contents of each one).
Image Segmentation
Given a picture, draw a pixel-level mask on a specific object.
Most Common supervised learning Algorithms are:
- Logistic Regression
- Linear Regressions
- K-nearest neighbors
- Decision Tree & Random Forest
- Neural Networks
- Support Vector Machines
Training Process
Training dataset consists of both inputs and outputs. The model will be trained until it detects the underlying patterns and relationships between the input data and the output labels. The accuracy will be measured through the loss function, adjusting until the error has been sufficiently minimized. That is the point where it reaches to global minima point.
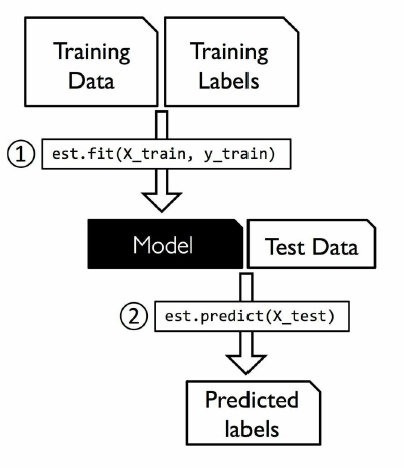
Over time, models try to learn, thus accuracy will normally be improved. When the training process is completed, these models are used to make new predictions on unseen data.
The predicted labels can be either numbers or categories. For instance, if we are predicting house prices, then the output is a number. So we called it regression model. When we are predicting spam emails using email filtering system, we have two choice whether email is spam or not. Therefore the output is categorical. This type model is known as classification model.
Training Process With a Real Example
Let us understand the training process with an example. For example we have a fruit basket which is filled up with different types of fruits. We want to categorize all fruits based on their category.
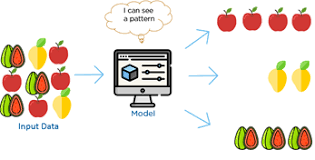
Our fruit basket is filled with Apples, Mango and Strawberries. For the models we will label fruits with corresponding unique characteristics of each fruits which make them unique by their type.
| No | Size | Color | Shape | Name |
| 1 | Big | Red | Circular shape with a depression at the top | Apple |
| 2 | Big | Yellow | Rounded top shape with a curved convergent shaped to the bottom. | Mango |
| 3 | Small | Red and Green | Oval shape with rough surface | Strawberries |
Now, the dataset is ready. It consists of different parameters called features and labels. Algorithm will learn the underlying pattern and output the results. Initially the output will not be so accurate but, as training time increase usually the model gets better and better. Once the model reaches to its best accuracy level, we feed new dataset called test dataset. This way we can make sure its learning progress and the accuracy.
Conclusion
In supervised learning, we train a machine learning algorithm using large set of data points. Some of the data points are labeled with target output. Our aim in supervised learning is to learn a model from labeled training data that allows us to make predictions about unseen or future data.
Learning resources:
- Python Machine Learning: Book by Sebastian Raschka
- Deep Learning with Python FRANÇOIS CHOLLET
- Hands‑On Machine Learning with Scikit‑Learn, Keras, and TensorFlow: Book by Aurelien Geron
- Medium post
- Krish Naik
- On medium post
- Deeplearningbook
- guru99.com
- techvidvan.com
- educba.com
- paperswithcode.com