

Chatbots have become increasingly popular in recent years, with many businesses and organizations turning to them as a way to improve customer service and streamline communication. One of the most advanced and powerful chatbots available is ChatGPT, developed by OpenAI. However, just like any technology, ChatGPT can be used for malicious purposes. In this article, we will explore how ChatGPT can be used for hacking and the potential risks it poses.
What is ChatGPT
ChatGPT is a large language model trained with ocean of data. It is used to generate human-like text and can be useful for a variety of natural language processing tasks, such as generating text, translating languages, summarizing long documents, and answering questions on almost any topics.
This means that it can have conversations with humans that are almost indistinguishable from those with another person. It is possible to say ChatGPT can be used by hackers to impersonate individuals or organizations, and do all sorts of nasty stuffs to trick people to reveal sensitive information.

Ways You can be Hacked
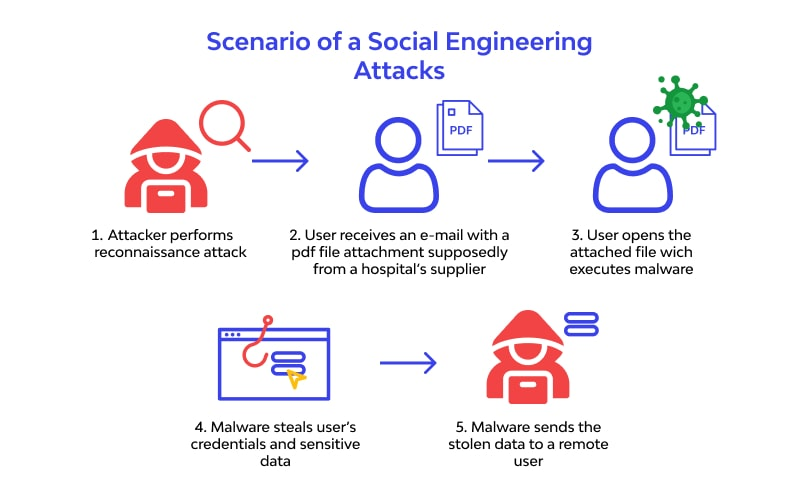
One way that ChatGPT can be used for hacking is through social engineering. Hackers can use the chatbot to impersonate a trusted individual or organization and trick people into providing personal information or login credentials. They can also use ChatGPT to create phishing scams, sending messages that contain malicious links or attachments.

Hackers can use the chatbot to gather information about a target, such as their interests and habits, which can be used to tailor future attacks. They can also use ChatGPT to map out a target’s network and identify potential vulnerabilities.
It’s also important to note that ChatGPT can be used to automate hacking techniques. For example, a hacker can use ChatGPT to create a script that automates the process of guessing passwords, increasing the chances of success.
Expert warn
OpenAI has implemented certain safety measures to prevent ChatGPT from being used for malicious purposes. For instance, it refuses certain requests that might be harmful or unethical activities such as generating malicious code, hate speech or false information. However, some users have discovered workarounds to bypass these safety measures, enabling them to use ChatGPT for malicious activities.
These workarounds include modifying the input to the model, using it in a different context or with a different objectives. For example, a user might use ChatGPT to generate seemingly harmless code, but then use it to launch a malicious attack.
Just recently a famous cybersecurity company, Check Point Software Technologies, has reported instances of ChatGPT being manipulated to create malicious code capable of stealing computer files, executing malware, phishing for credentials, and even encrypting an entire system in a ransomware attack.
“We’re finding that there are a number of less-skilled hackers or wannabe hackers who are utilizing this tool to develop basic low-level code that is actually accurate enough and capable enough to be used in very basic-level attacks,” Rob Falzon, head of engineering at Check Point, told CBC News.
Another experts in the field said, ChatGPT could significantly speed up and simplify cybercrimes activities for unethical hackers. They just need to identify a clever way to ask the correct questions to the bot.
According to Shmuel Gihon, security researcher, ChatGPT is a great tool for software developers to write better code. However he also, pin pointed the advantages any bad actors might take with this tool.
“As a threat actor, if I can improve my hacking tools, my ransomware, my malware every three to four months, my developing time might be cut by half or more. So the cat-and-mouse game that defense vendors play with threat actors could become way harder for them.”
TechCrunch reported, they tried to create a realistic phishing email using ChatGPT. The chatbot initially refused to create malicious content, but with a slight change in wording, they were able to generate it. They have interviewed number of experts in security industry, and many have believed its potential to generate bad activities for hackers.
Principal research scientist at Sophos, Chester Wisniewski, have said people could do all sorts of social engineering attacks using ChatGPT.
“At a basic level, I have been able to write some great phishing lures with it, and I expect it could be utilized to have more realistic interactive conversations for business email compromise and even attacks over Facebook Messenger, WhatsApp, or other chat apps,” Wisniewski told TechCrunch.
According infosecurity-magazine, a Russian cyber-criminals have been observed on dark web forums trying to bypass OpenAI’s API restrictions to gain access to the ChatGPT chatbot for nefarious purposes. They have been observed for discussing how to use stolen payment cards to pay for upgraded users on OpenAI and blog posts on how to bypass the geo controls of OpenAI. Some of them still have created tutorials explaining how to use semi-legal online SMS services to register to ChatGPT.
“Right now, we are seeing Russian hackers already discussing and checking how to get past the geofencing to use ChatGPT for their malicious purposes.” said Sergey Shykevich, threat intelligence group manager at Check Point Software Technologies.
According to a recent report from WithSecure, a Helsinki-based cybersecurity company, malicious actors may soon be able to exploit ChatGPT by figuring out how to ask harmful prompts, potentially leading to phishing attempts, harassment, and the dissemination of false information.
“At the beginning, it might have been a lot easier for you to not be an expert or have no knowledge [of coding], to be able to develop a code that can be used for malicious purposes. But now, it’s a lot more difficult,” Karimipour said.
Taking measures by OpenAI
It is important to note that while OpenAI has implemented safety measures to prevent the abuse of ChatGPT, it is still possible for malicious actors to bypass these measures. This highlights the need for individuals and organizations to be aware of the potential risks associated with advanced technologies such as ChatGPT and to take appropriate security measures to protect against hacking attempts.
OpenAI is actively working to improve the safety of their product and respond to potential threats and workarounds identified by cybersecurity experts. According to Hadis Karimipour, an associate professor, OpenAI has refined their safety measures to prevent ChatGPT from being used for malicious purposes over the past few weeks.
“At the beginning, it might have been a lot easier for you to not be an expert or have no knowledge [of coding], to be able to develop a code that can be used for malicious purposes. But now, it’s a lot more difficult,” Karimipour said.
Every new innovation has its pros and cons. The implementation of such applications undergoes ongoing improvements and follows specific strategies to ensure maximum safety evaluations, and that the case of ChatGPT too.
Conclusion
Overall, ChatGPT is a powerful and versatile tool that has the capability to change the way businesses communicate with their customers and clients. However, it’s crucial to be aware of the possible risks and take necessary security precautions to defend against hacking attempts. By being cautious and proactive, organizations and individuals can continue to benefit from ChatGPT while minimizing the potential dangers.
















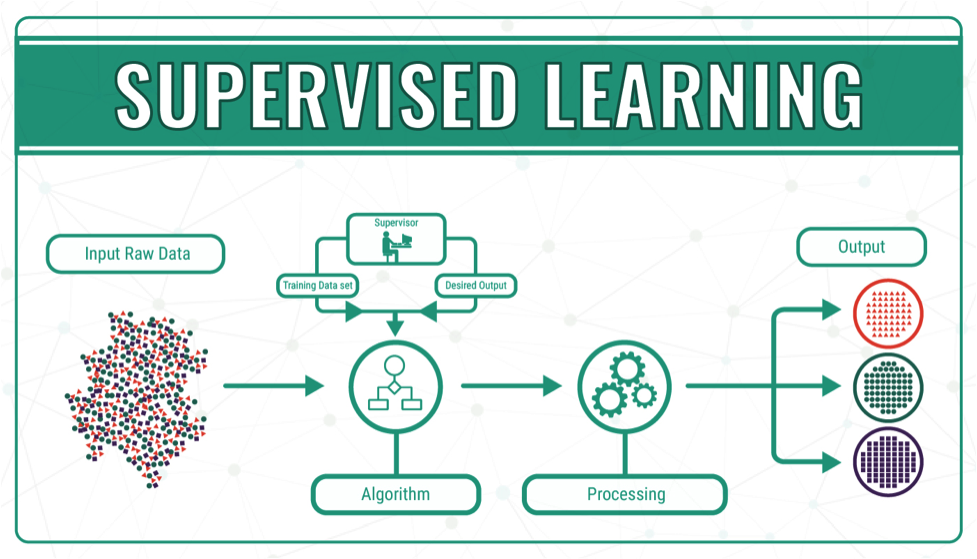

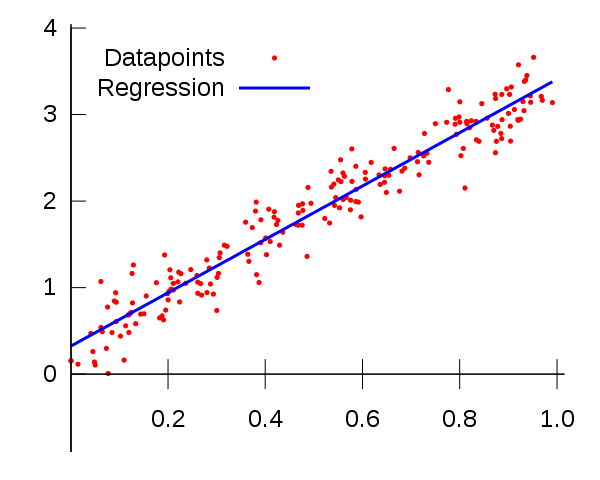
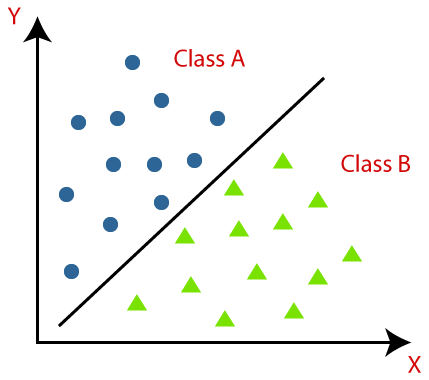
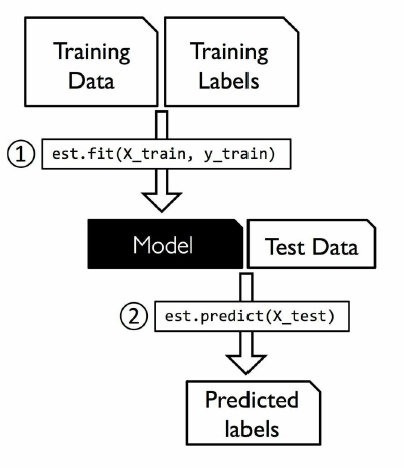

![\[X_{new} = \frac{ Xi-min(X)}{max(X)-min(X)}\]](https://letmefail.com/wp-content/ql-cache/quicklatex.com-7c25e0d84a7575027d5eb9f4e3375a14_l3.png "Rendered by QuickLaTeX.com")
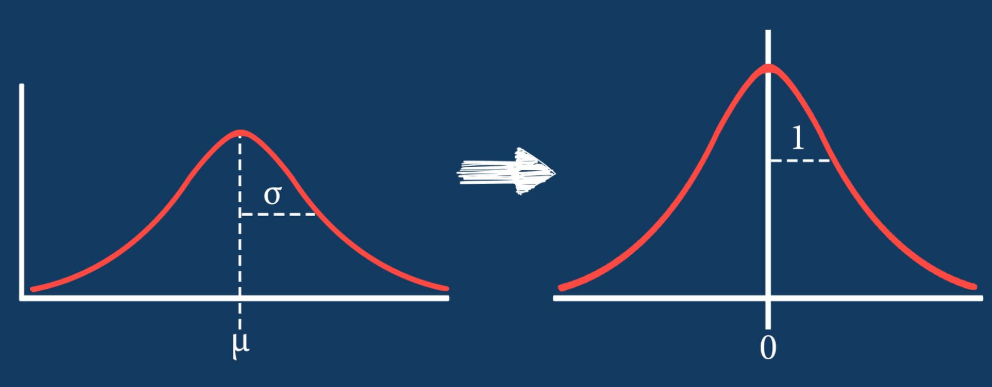
![\[ X_{new} = \frac{Xi-X_{mean}}{Standard Deviation} \]](https://letmefail.com/wp-content/ql-cache/quicklatex.com-a990c2b6a2d746eb6642adf6e47634f4_l3.png "Rendered by QuickLaTeX.com")