

ChatGPT – What is it?
ChatGPT is a large language model trained by OpenAI for generating human-like text. It can be useful for a variety of natural language processing tasks, such as generating text, translating languages, summarizing long documents, and answering questions. Because it is trained on a massive amount of text data, it has a wide range of knowledge and can generate text that is difficult for other models to produce. However, like all language models, ChatGPT has limitations and may not always produce accurate or appropriate text, so it should be used with caution.
It is not capable of making decisions or taking actions on its own. It is up to users to decide how to use ChatGPT and other AI technologies, and it is ultimately the responsibility of human beings to determine how they will be used and how they will impact society.
Facts about ChatGPT:
- Created by OpenAI.
- Organization founded by some of high profile entrepreneurs including Elon Musk, Sam Altman in 2015.
- Valued at around $20 billion.
- Other products including, DALL·E 2 and Whisper
- ChatGPT is powered by GPT-3.5 series
- Crossed 1 million users in just 5 days
Why is it important and how can we use it?
For chat – Simple chat
As the name suggests you can use ChatGPT simply to chat. Ask almost anything then it will give you accurate answers. ChatGPT is a chatbot that helps in generating content for digital marketing campaigns. It’s not just a text generator, this bot also tracks all the conversations and interactions with the audience on a website. It monitors when visitors are browsing and views the website, clicks links and leaves comments.
In short, just ask something and you will get a response, mostly sensible responses – may occasionally generate incorrect information.
Write, debug and code explaining
If you are a programmer, this is huge news for you. You can now use ChatGPT to write and debug code. The app not only write code but also fixes bugs and generates explanation for the code it writes.
The development process might significantly become faster and cheaper if we are able to use AI powered apps to write code. It seems this is happening and it is just beginning.
ChatGPT explains complex topics and concepts related to programming almost equally human levels and I’m wondering what’s stopping it from becoming an alternative to human coders.
For creative writing
Large language models are really good at generating coherent text with structured approach. ChatGPT does the same, structuring creativity with ChatGPT is easier than ever with little guidance and observation. It is able to handle more complex instructions and producing longer-form content such as Poem, Fiction, Non-Fiction and even long form text based essays.
ChatGPT is able to keep track of what has been said previously and use that information to generate appropriate responses. It generates formal or informal text, short and long form, depending on the context and the tone of the conversation. This tool can be beneficial for creating content for social media or other online platforms.
A user asking the chatbot to explain a regular expression and write a short essay on “effects of westward expansion on the civil war”. In both cases, it was incredibly creative too delivering pretty good results.
Deploy a virtual virtual machine (VM)
Jonas Degrave, a researcher showed how he turned ChatGPT into what appears to be a full fledged Linux terminal interacting with the VM here created right from your web browser. A Virtual Machine running inside ChatGPT feels like magic. See the written article by Jonas here.
Security
We not surprised at all, people are using it for various purposes. Some users are using ChatGPT to reverse engineer shellcode, rewrite it in C and others are playing with it to generate nmap scans.
Limitation
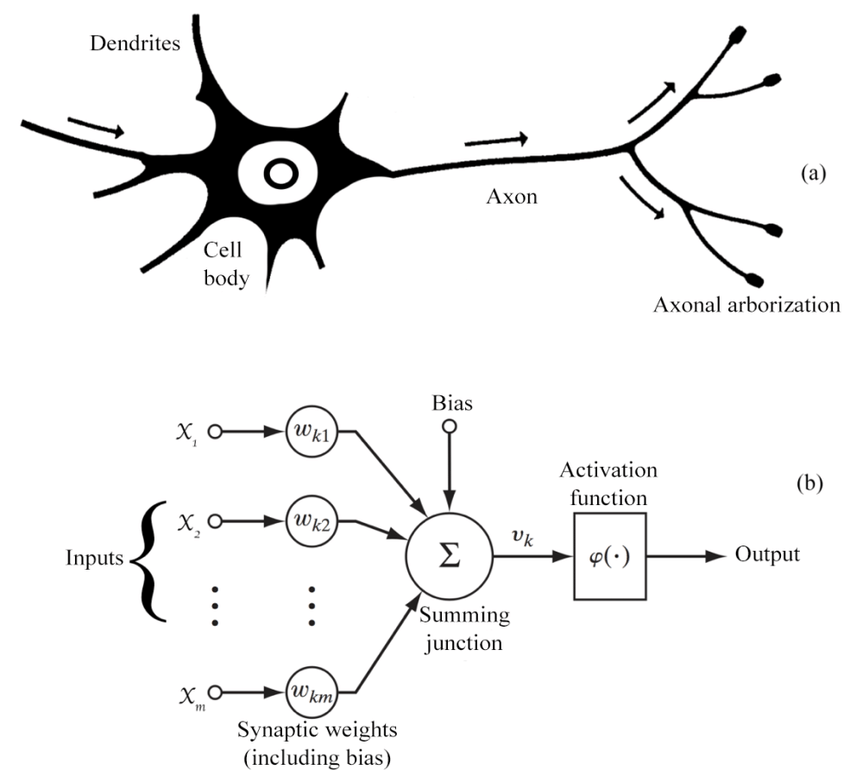
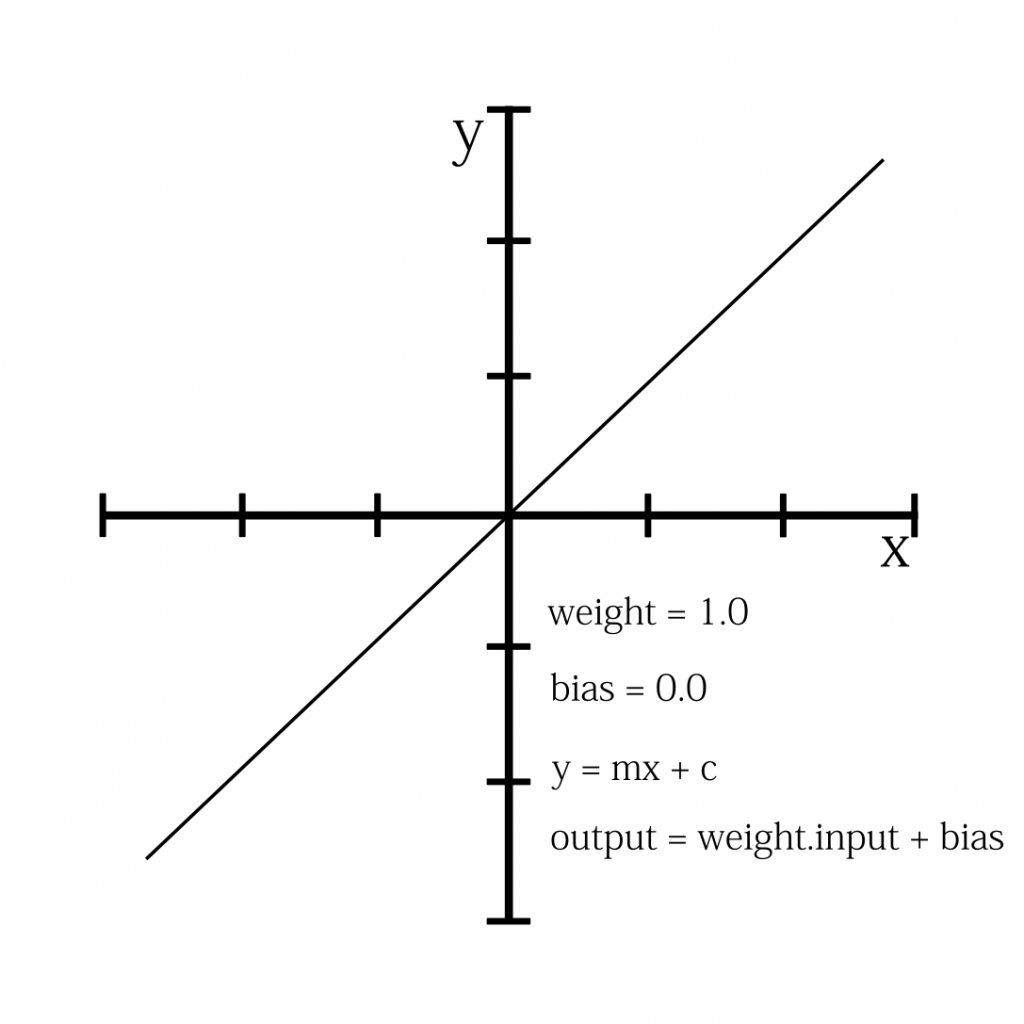
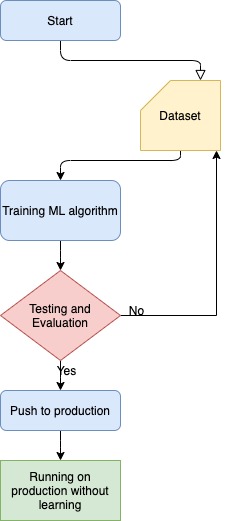
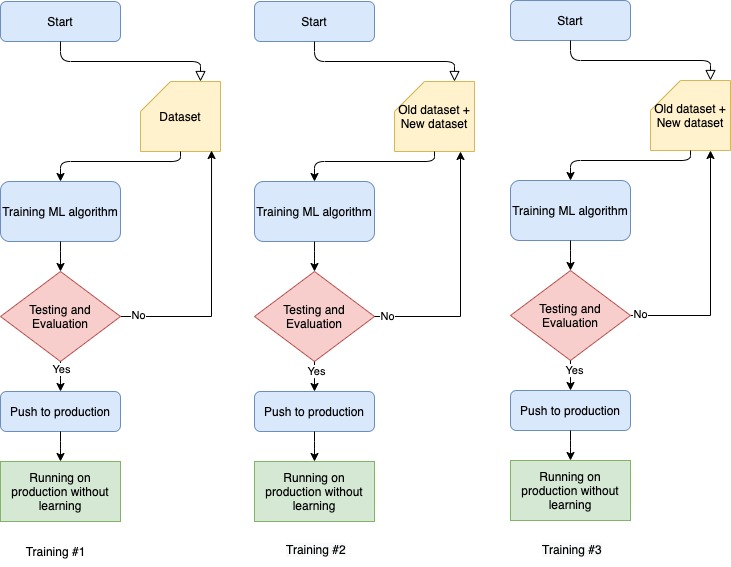
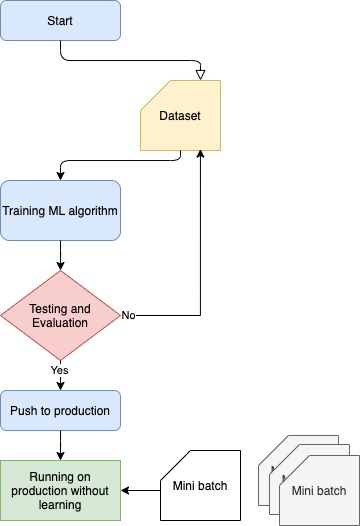
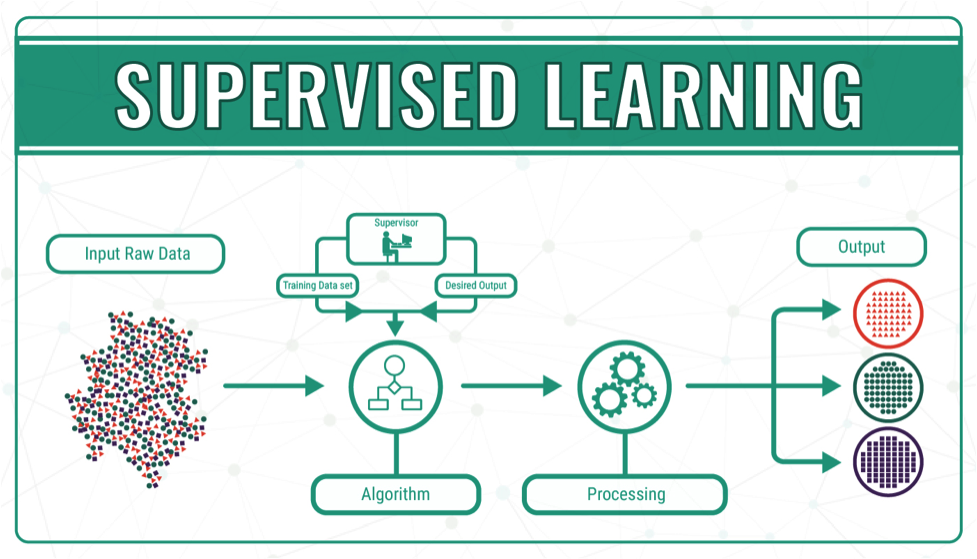
Like any other machine learning model, it is only as good as the data it has been trained on. This means that it may not be able to provide accurate answers to questions or generate responses that are outside of the scope of the data it has been trained on. Additionally, ChatGPT is a text-based model, so it is not capable of providing visual or audio responses. Finally, ChatGPT is not able to browse the internet or access external information, so it can only provide information that it has been trained to generate based on the input it receives. You can see the capabilities and limitations of ChatGPT in the picture below.

Wrap up
We are currently experiencing a huge development in this space, thanks to ChatGPT. ChatGPT is taking the world by storm. It can be used in various areas, including social media content generator, voice assistance, chatbots and virtual assistants, customer care application, meetings, code generators, and for security research areas. This opens the door for a new generation of chatbot innovation, possibly the kind that many anticipated but didn’t see come to pass. At least up till this point.










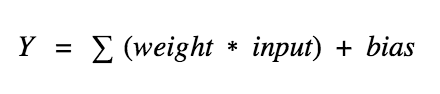

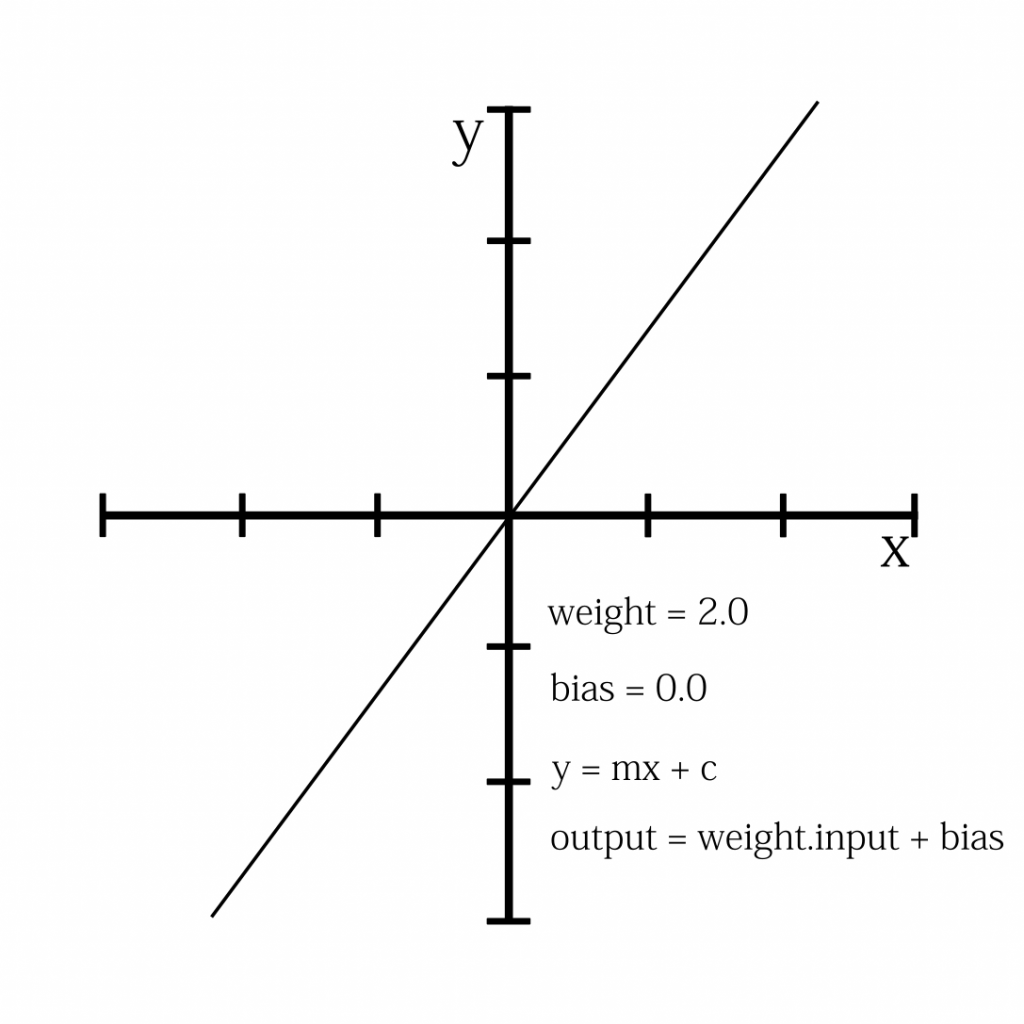
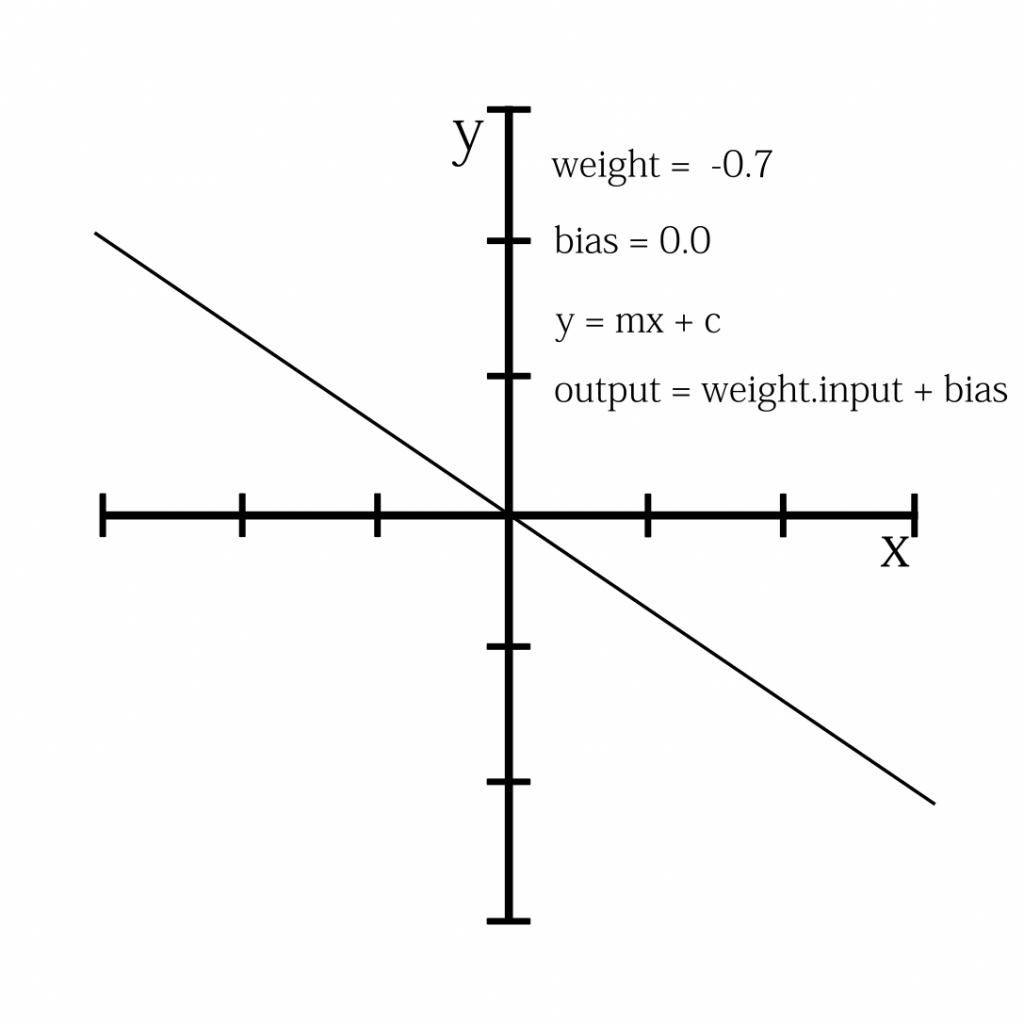
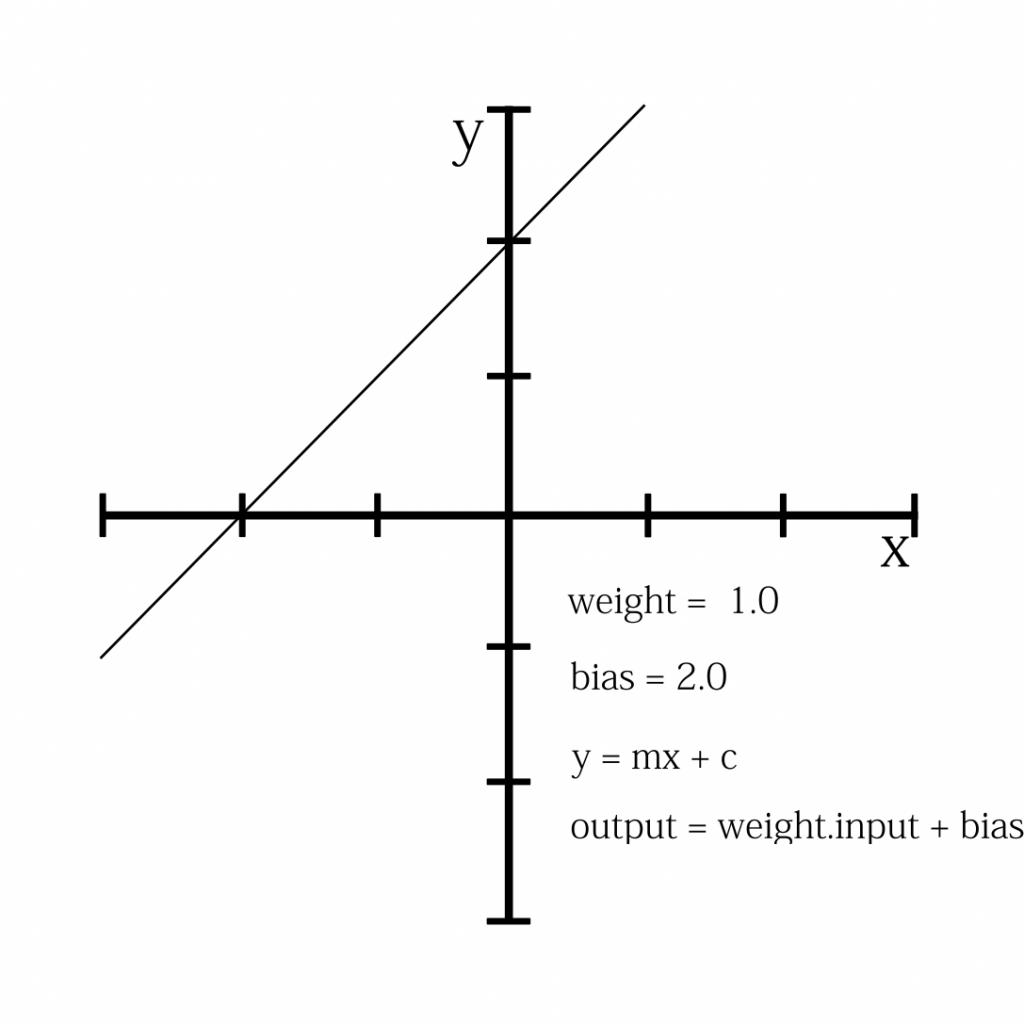
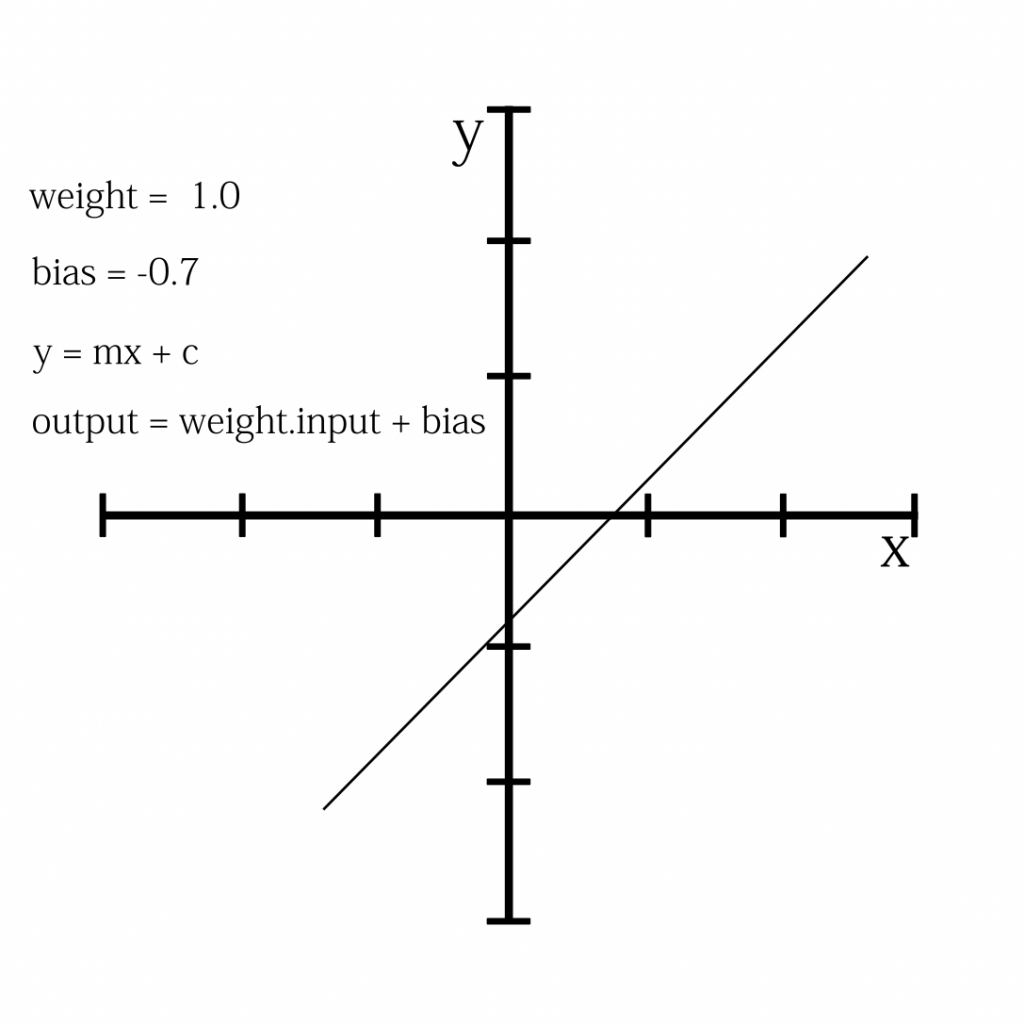








![\[X_{new} = \frac{ Xi-min(X)}{max(X)-min(X)}\]](https://letmefail.com/wp-content/ql-cache/quicklatex.com-7c25e0d84a7575027d5eb9f4e3375a14_l3.png "Rendered by QuickLaTeX.com")
![\[ X_{new} = \frac{Xi-X_{mean}}{Standard Deviation} \]](https://letmefail.com/wp-content/ql-cache/quicklatex.com-a990c2b6a2d746eb6642adf6e47634f4_l3.png "Rendered by QuickLaTeX.com")